In my previous post on card shuffling, I established a basic framework in which we will work. We are given a probability distribution 

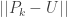
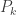

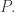
The standard shuffling technique is called the “riffle shuffle.” In this shuffle, the deck is cut in half, and the two halves are zippered together. We need to come up with a mathematical way of describing the riffle shuffle, and I’ll list three different methods (I’m assuming the deck has 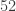

First Way. The first thing to think about is how we cut the deck. Mathematically speaking, we will assume the number of cards in the top half of the deck after we cut is binomially distributed. All this means is that to determine the number of cards we cut from the top, flip 52 coins and count the number of heads to figure out how many cards go in the top half. It may seem strange that there is a positive probability of having all 52 cards in the deck sitting in the “top half” but the probability is extremely small and so doesn’t matter so much. For most shufflers, the size of the two “halves” are often quite different. Anyway, suppose that our result is 



 norm of the function minus its average value (this is known as a BMO norm) is controlled by the
norm of the function minus its average value (this is known as a BMO norm) is controlled by the  . This theorem is almost universally interesting in and of itself. Additionally, it will give ample reason as to why people — myself included — care about objects called singular integral operators. This will also provide some impetus for some future posts as well, particularly one which will outline a famous construction of Fefferman and give some reasons why harmonic analysis in higher dimensions is distinctly harder than in dimension 1.
. This theorem is almost universally interesting in and of itself. Additionally, it will give ample reason as to why people — myself included — care about objects called singular integral operators. This will also provide some impetus for some future posts as well, particularly one which will outline a famous construction of Fefferman and give some reasons why harmonic analysis in higher dimensions is distinctly harder than in dimension 1.
{kind=link}